← Back to Projects Deep Learning Infrastructure 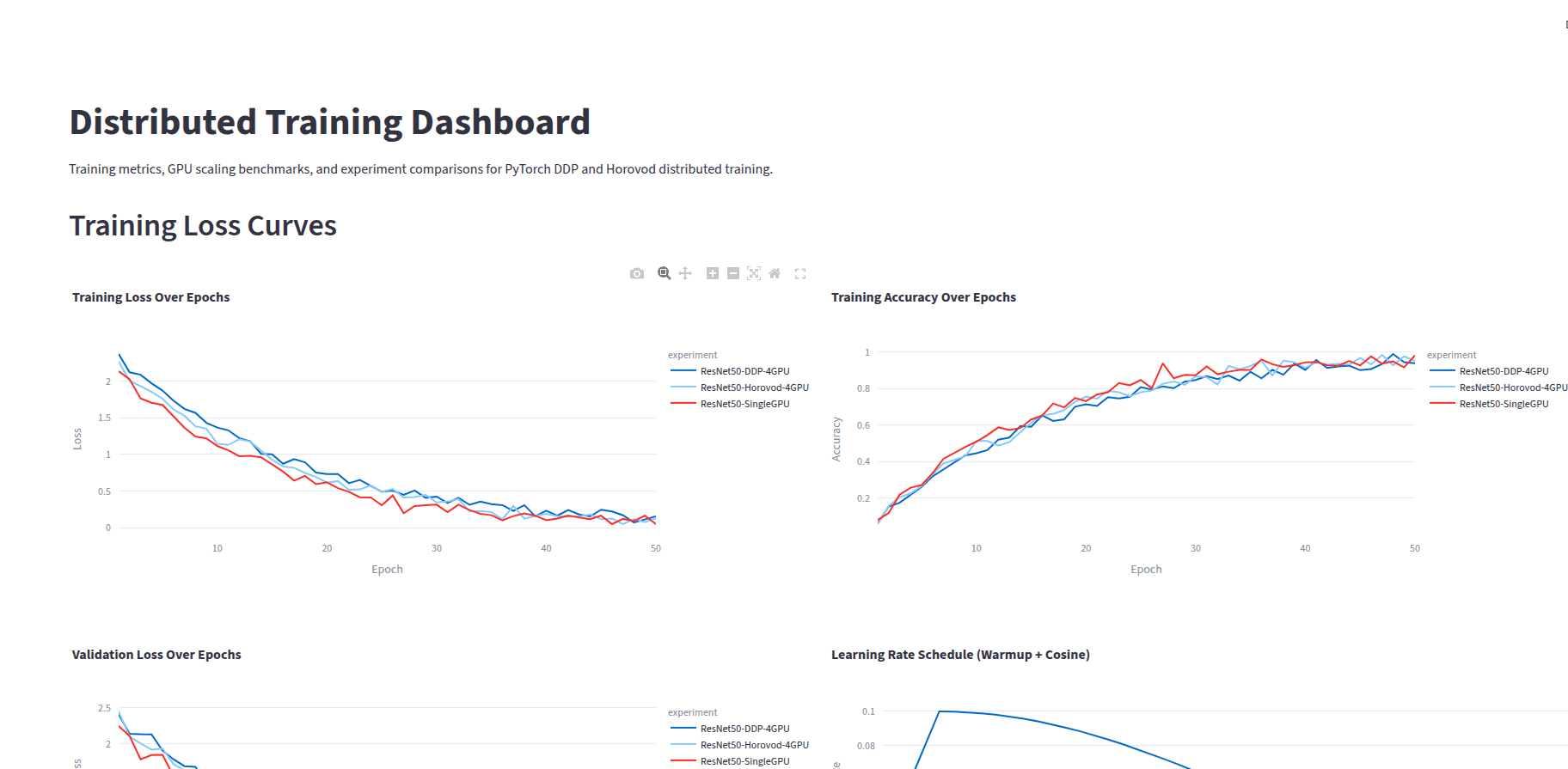
Distributed Training Framework
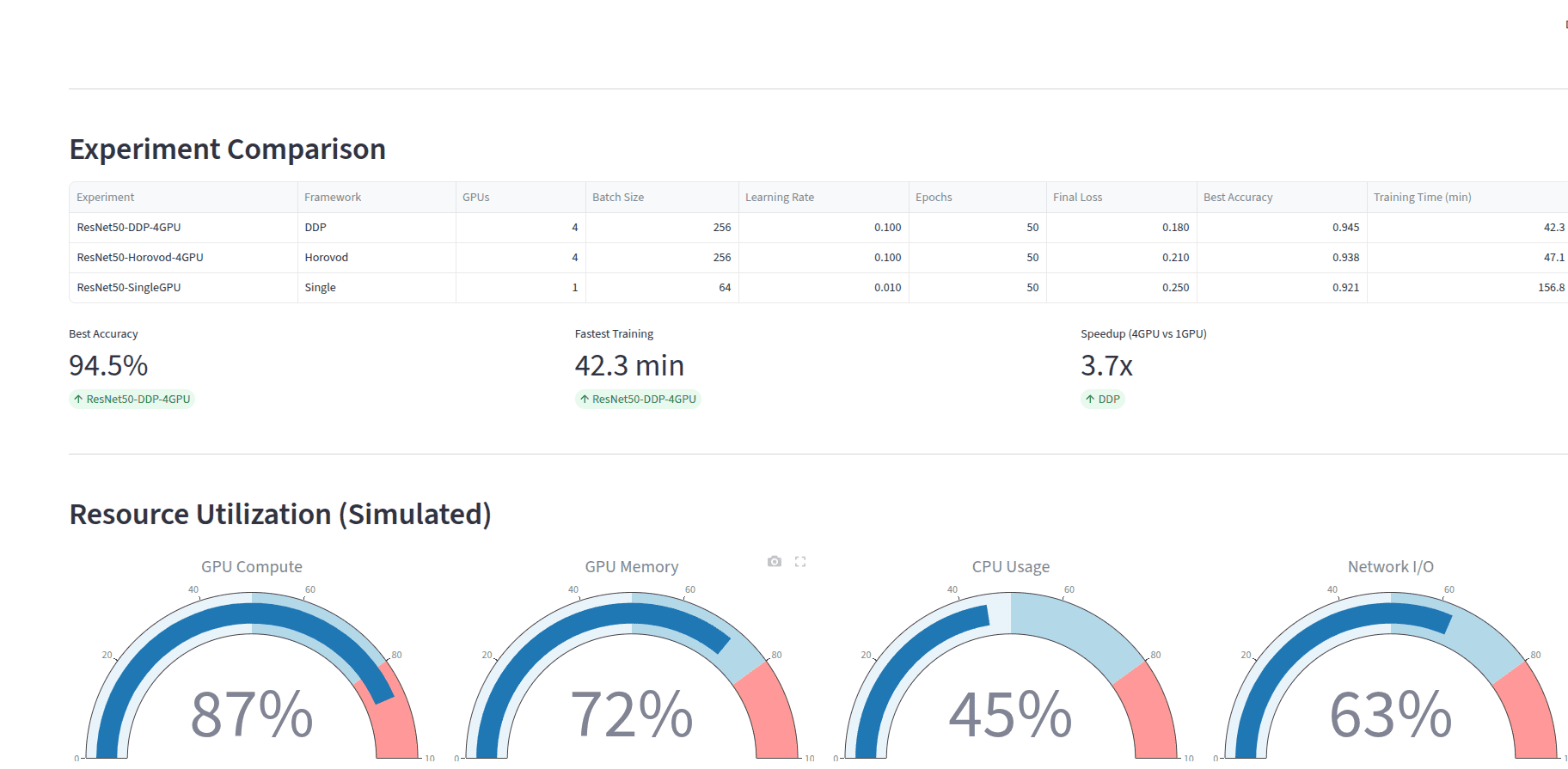
Multi-GPU training using PyTorch DDP and Horovod, with Ray Tune hyperparameter optimization, mixed precision training, and Weights & Biases experiment tracking.
Overview
Distributed training framework for scaling deep learning across multiple GPUs with experiment tracking.
Architecture
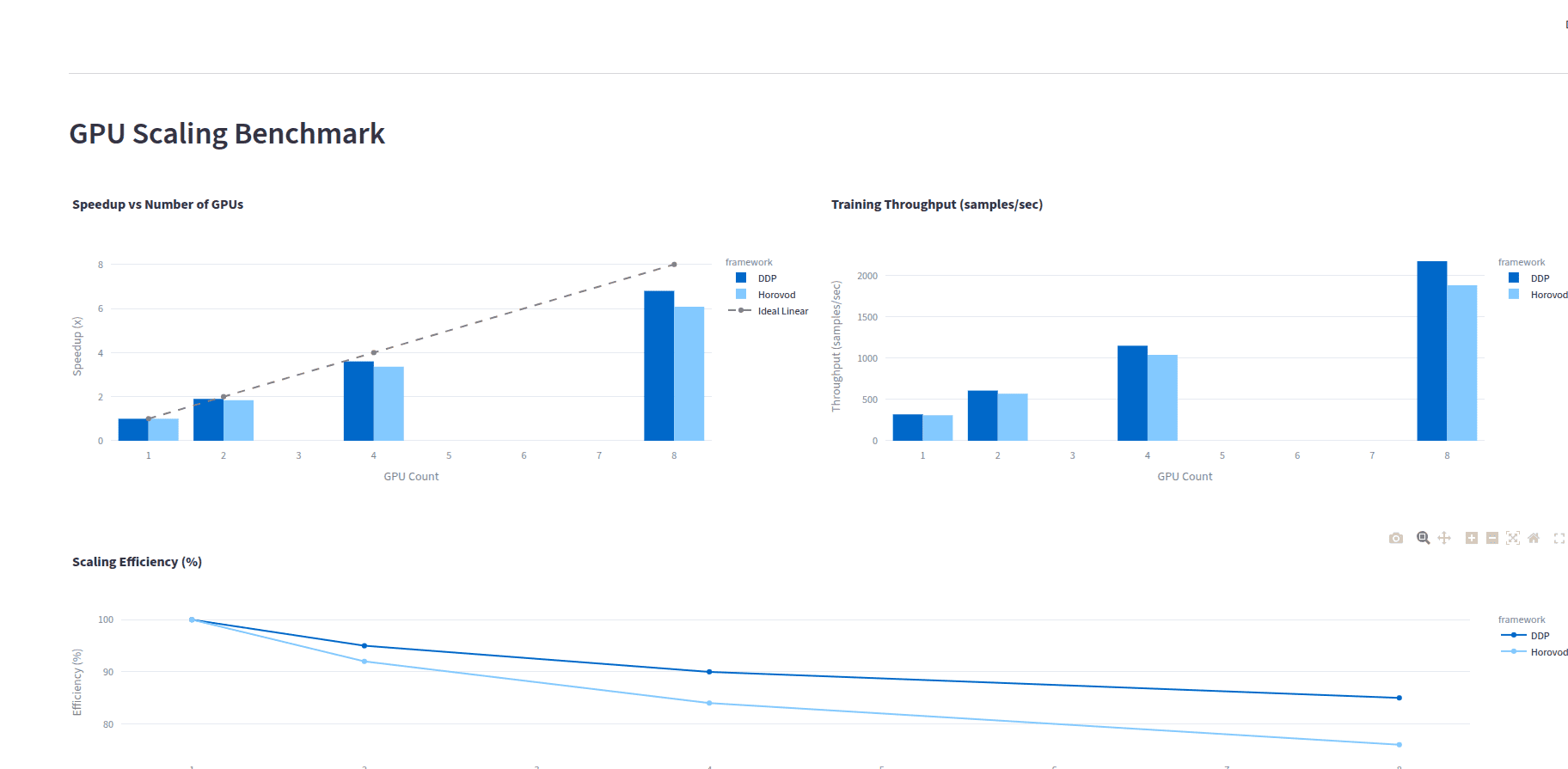
- PyTorch DistributedDataParallel for multi-GPU training
- Horovod integration for framework flexibility
- Ray Tune for distributed hyperparameter search
- Mixed precision training with torch AMP
- Weights & Biases for experiment tracking
Key Features
- Linear scaling across multiple GPUs
- Mixed precision for faster training
- Distributed hyperparameter optimization
- Comprehensive scaling benchmarks