← Back to Projects Document Processing 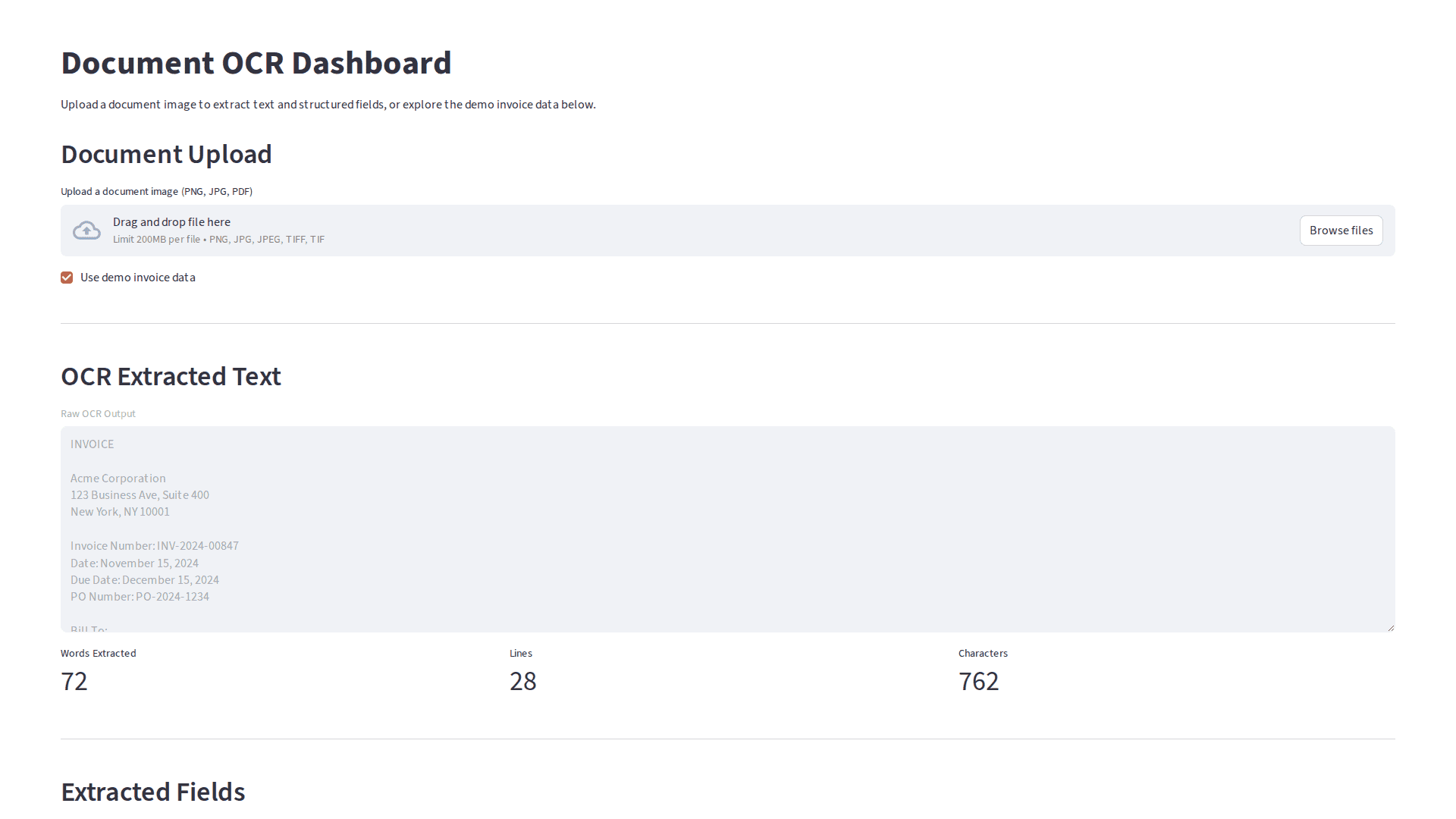
Document Intelligence OCR System
End-to-end document processing combining Tesseract OCR, OpenCV preprocessing, and transformer-based extraction to extract structured data from invoices and receipts.
Overview
Intelligent document processing pipeline for automated data extraction from invoices and receipts.
Architecture
- OpenCV preprocessing for image enhancement
- Tesseract OCR for text extraction
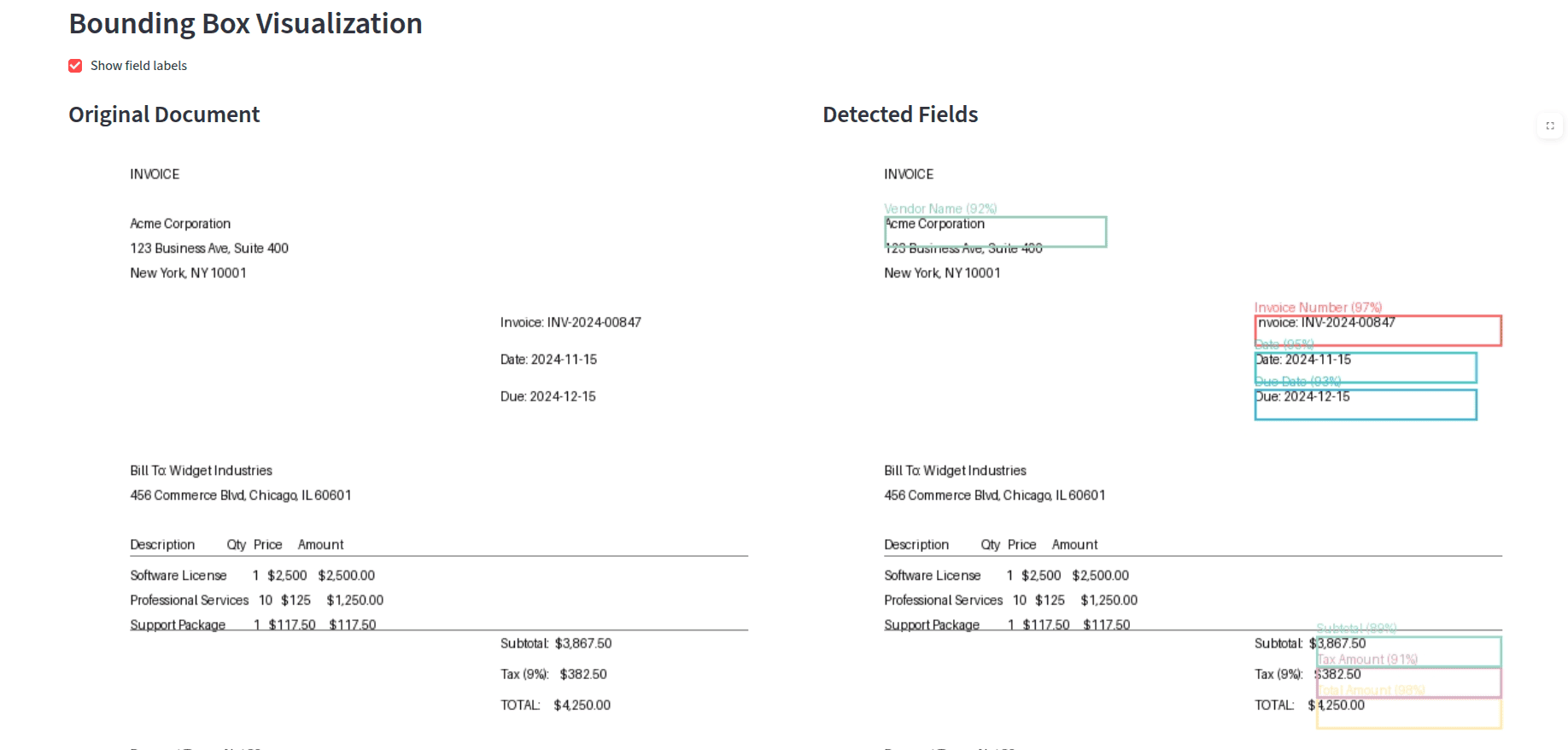
- LayoutLM/Donut for structured field extraction
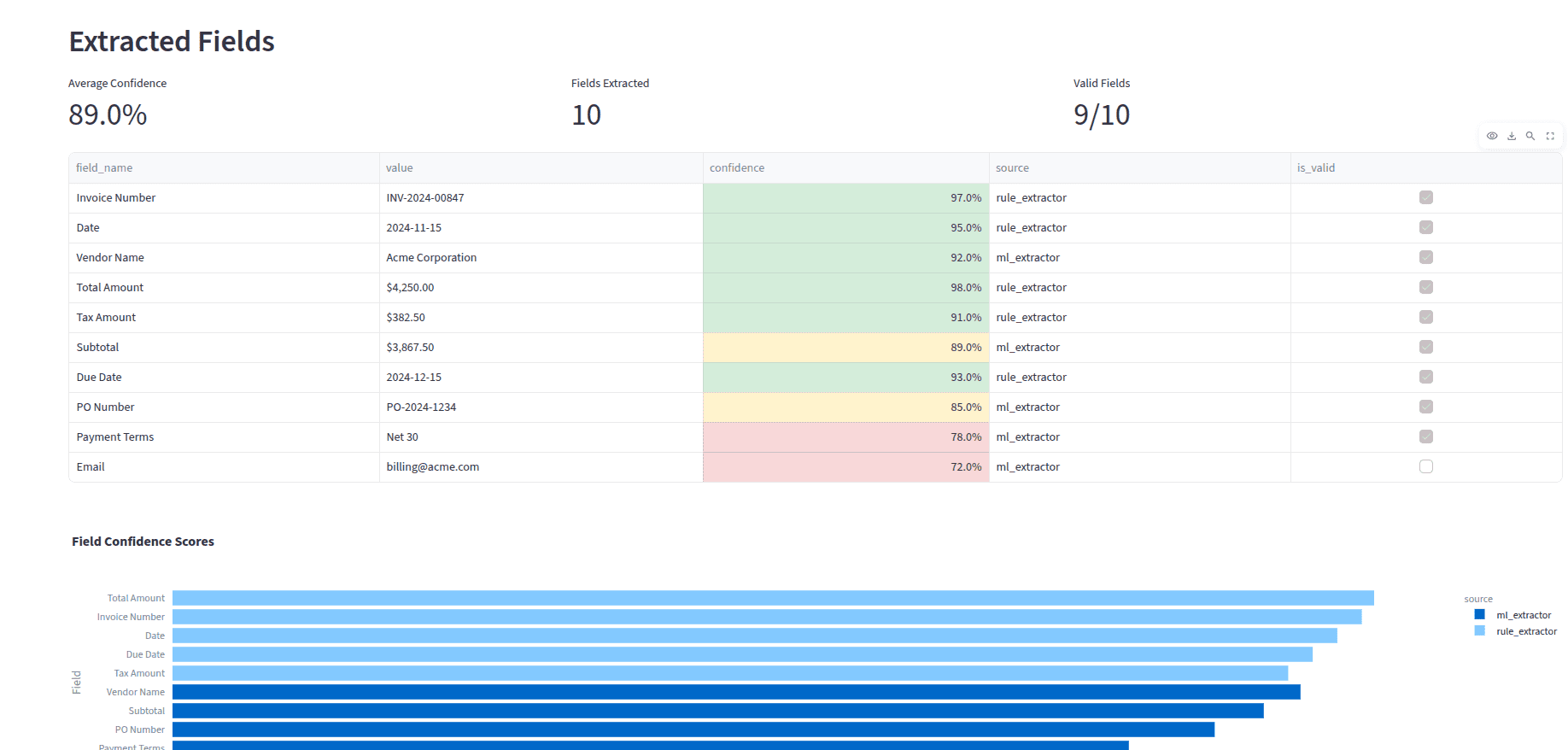
- Validation rules and confidence scoring
- FastAPI serving endpoint
Key Features
- Multi-format document support (PDF, images)
- Field-level confidence scoring
- Custom validation rules per document type
- Batch processing capability