← Back to Projects LLM Engineering 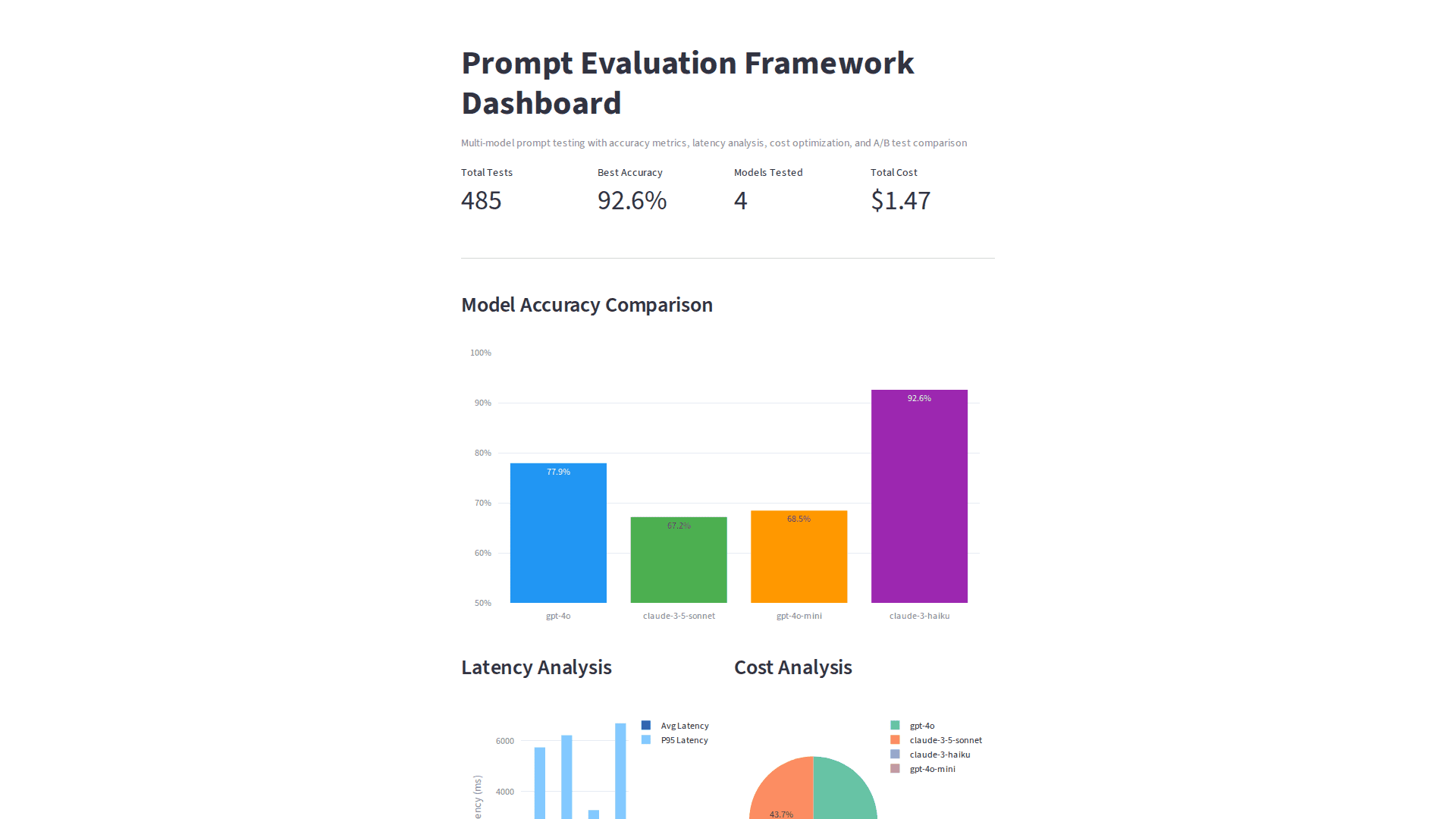
Prompt Evaluation Framework
Testing suite for LLM prompts with multi-model evaluation (GPT-4, Claude), A/B testing with statistical significance, cost optimization, and version control for prompts.
Overview
Comprehensive framework for systematic evaluation and optimization of LLM prompts.
Architecture
- Multi-model evaluation (GPT-4, Claude)
- A/B testing with statistical significance
- Cost tracking and budget limits
- Prompt version control and history
- Interactive HTML report generation
Key Features
- Cross-model prompt comparison
- Statistical significance testing
- Cost optimization with budget controls
- Version-controlled prompt iterations