Tunley Environmental just launched a dedicated Climate Risk and Resilience Strategy service. Arcadis partnered with Jupiter Intelligence to scale physical climate risk analytics globally. PwC published a 12-month roadmap for CSRD and California climate disclosure readiness. The signal is clear: climate risk disclosure has moved from a compliance checkbox to a full-blown data engineering challenge.
But here is the part most sustainability consultancies skip over. Regulatory frameworks like CSRD do not just ask companies to “assess climate risk.” They require granular, asset-level, scenario-based quantitative data, updated on defined cycles, with audit-grade traceability. That is not a strategy problem. That is a data pipeline problem. And most organizations are not ready.
The 2026 disclosure landscape is fragmented, not simplified
ESG Dive reported that companies now face a “fragmented climate risk disclosure landscape” after the U.S. and EU diverged on regulatory consensus in 2025. Thomson Reuters flagged ESG compliance among the top 10 global concerns for 2026. And A&O Shearman noted that ESG-driven enforcement is “continuing to mature” beyond soft-law expectations.
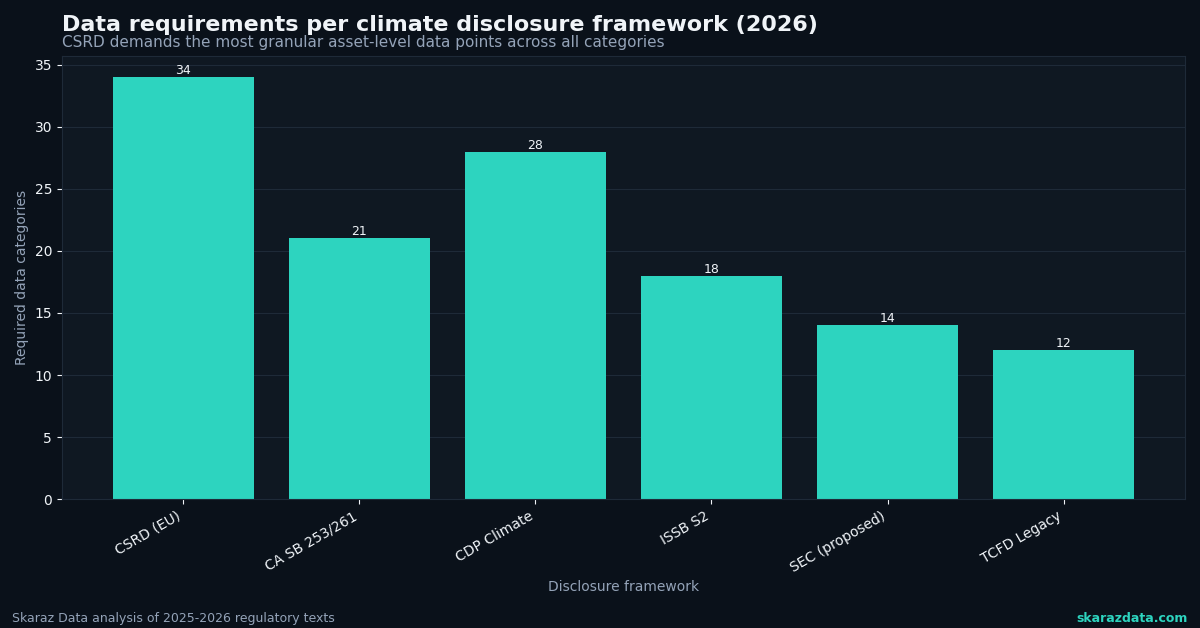
For data teams, fragmentation means one thing: you cannot build a single pipeline and call it done. CSRD (EU), California SB 253/261 (U.S.), CDP (global), and ISSB-aligned frameworks each have overlapping but distinct requirements around scenario analysis, Scope 3 emissions, physical risk metrics, and transition planning. Your data architecture needs to serve multiple reporting endpoints from a shared analytical core.
The practical implication: design for modularity from day one. A monolithic reporting tool that only outputs CSRD-formatted tables will need expensive rework when CDP expands its disclosure scope (as Morningstar confirmed it will in 2026) or when California enforcement timelines accelerate.
What CSRD actually requires from your data stack
Let’s get specific. ESRS E1 (Climate Change) under CSRD demands several categories of quantitative output that most corporate data teams have never had to produce:
- Physical risk exposure by asset and geography. This means geocoded asset registers linked to hazard layers (flood, heat stress, wildfire, sea-level rise) under at least two IPCC scenarios (typically SSP2-4.5 and SSP5-8.5). You need spatial resolution of 1 km or finer for credible results.
- Transition risk metrics tied to financial projections. Carbon pricing scenarios, policy pathway modeling, and sector-specific decarbonization curves. Supply Chain Brain highlighted that ROI-driven decarbonization is gaining traction, which means your transition models need to connect to actual P&L impact, not abstract carbon budgets.
- Scope 1, 2, and 3 emissions with methodological transparency. CDP’s 2026 cycle is expanding requirements here. Your pipeline needs to track emission factors, data sources, estimation methods, and uncertainty ranges.
- Double materiality assessment outputs. Both financial materiality (how climate affects the business) and impact materiality (how the business affects the climate), quantified where possible.
- Time horizons of short (0-5 years), medium (5-15 years), and long-term (15-30+ years) for each risk category.
This is not something you solve with a spreadsheet and a consultant’s PDF. It requires automated data ingestion, spatial joins, scenario engines, and reproducible analytical pipelines.
The datasets your team needs to source now
One of the biggest bottlenecks I see with clients is dataset procurement. Teams know they need climate projections but do not know which ones, at what resolution, or how to integrate them. Here is a practical starting list:
- CMIP6 downscaled projections (NASA NEX-GDDP-CMIP6 provides daily data at ~25 km, but you will likely need statistical or dynamical downscaling to 1 km for asset-level work)
- Copernicus Climate Data Store (CDS) for ERA5 reanalysis (historical baseline), seasonal forecasts, and European-focused hazard indicators
- OpenStreetMap and national cadastral data for asset geolocation and building footprint extraction
- FATHOM or JBA flood maps for pluvial, fluvial, and coastal flood hazard layers (commercial, but increasingly required for credible physical risk assessments)
- Global Forest Watch and FIRMS for wildfire exposure and land-use change
- NGFS climate scenarios for transition risk modeling (central bank-endorsed, increasingly expected by auditors)
The critical point: raw data is not enough. You need reproducible transformation pipelines that convert these sources into asset-level risk scores with full provenance tracking. Every number in your CSRD report needs to trace back to a specific dataset version, processing step, and methodology.
Three architecture decisions that will save you six months
Based on building these systems for multiple clients, here are three decisions I recommend making early:
1. Separate your hazard engine from your reporting layer. Your climate hazard computations (spatial overlays, return period calculations, scenario interpolation) should live in a reusable analytical core. Your reporting layer should pull from this core and format outputs for CSRD, CDP, or any other framework. This is the modularity principle in practice.
2. Version everything, including your input data. Climate datasets get updated. Emission factors change. IPCC scenarios evolve. If you cannot reproduce last year’s risk assessment with last year’s data, you will fail the assurance process. Use data versioning tools (DVC, LakeFS, or even structured S3 prefixes) from the start.
3. Automate your materiality scoring. Double materiality is not a one-time workshop exercise under CSRD. It needs to be refreshed as your asset portfolio, supply chain, and the physical climate evolve. Build scoring models that can be re-run with updated inputs, not static matrices locked in a slide deck.
The gap between strategy and execution
Ricardo identified sustainability reporting as a top priority for 2026. Ropes & Gray published 26 predictions for compliance professionals. PwC outlined five strategic moves for reporting readiness. The advisory layer is well-covered.
What is missing is the execution layer: the data scientists and engineers who can actually build the pipelines, run the spatial analyses, validate the models, and deliver audit-ready outputs. Most sustainability consultancies excel at strategy and framework interpretation. Far fewer can write the Python, build the geospatial workflows, and deploy the infrastructure that turns climate data into disclosure-ready metrics.
That gap is exactly where Skaraz Data operates. We help organizations build the technical backbone of climate risk disclosure: from raw satellite and climate data through to automated, reproducible reporting pipelines that serve CSRD, CDP, and beyond. If your team is staring at a 2026 disclosure deadline and wondering how to move from strategy decks to working data infrastructure, let’s talk.