IFRS S2 is being managed in most listed companies as a sustainability reporting program. That framing will hold up until the first audit cycle, at which point it breaks.
The standard, issued by the ISSB and now adopted in jurisdictions covering the majority of global market capitalisation, requires listed firms to disclose climate-related financial information that is comparable, restated each year, and traceable to source. That last word is the one most teams have not internalised. Climate disclosure is now subject to the same data lineage requirements as the rest of the financial statements.
The data is not the problem
The hard part of IFRS S2 was supposed to be the science: choosing scenarios, modeling physical risk, building transition pathways. In practice, most teams have functional answers to those questions within a quarter. NGFS scenarios are public. Hazard layers are vendor-licensed. Internal carbon pricing is a board decision.
What breaks is the supply chain underneath those answers.
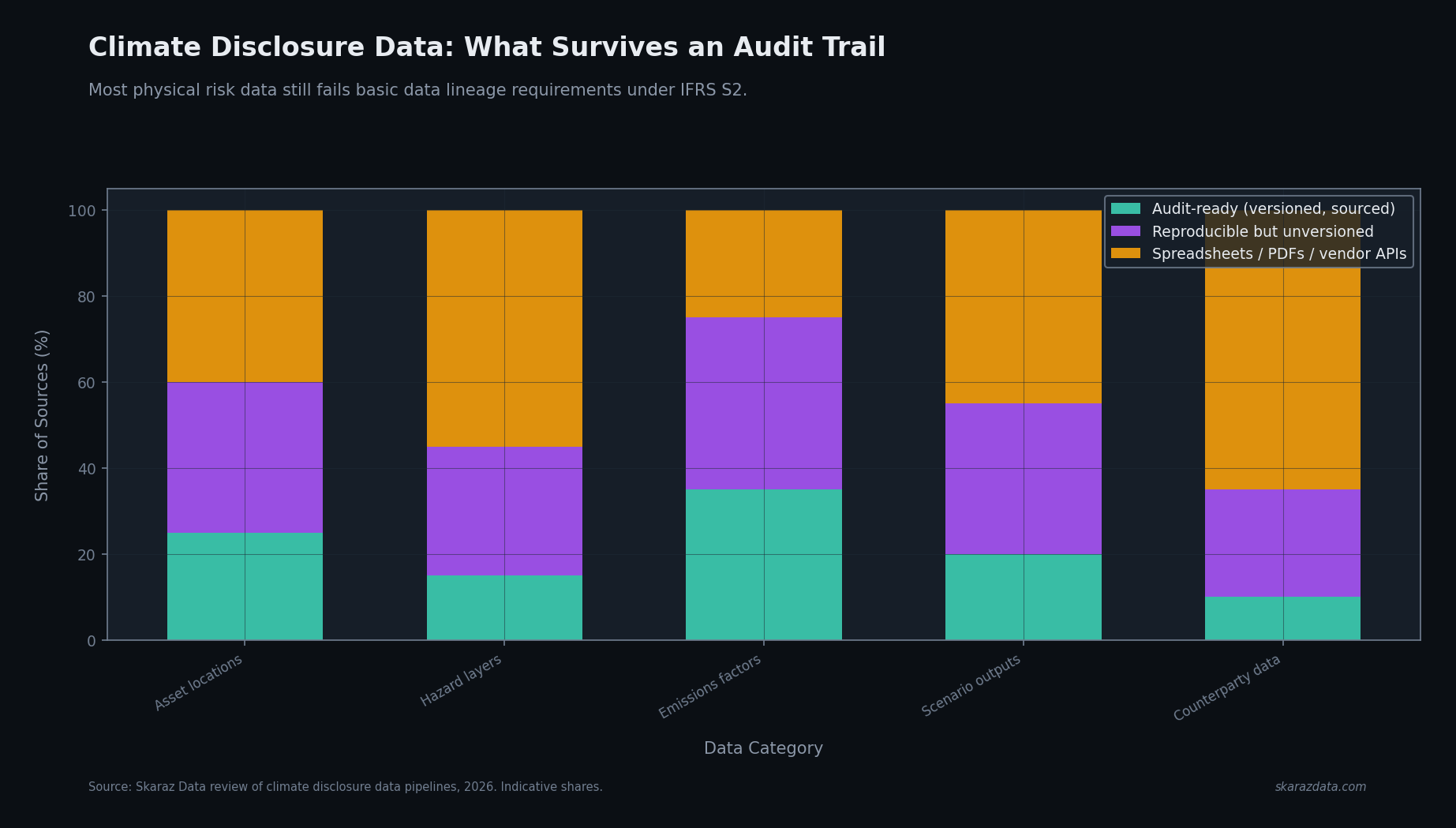
A climate disclosure draws on at least five distinct data categories, each with its own provenance problem:
- Asset locations. Often pulled from procurement systems, real estate registers, or operations spreadsheets. Frequently incomplete for leased or third-party-managed sites. Almost never versioned in the financial reporting sense.
- Hazard layers. Delivered as raster files, vendor APIs, or PDFs. Updated on vendor schedules, not corporate ones. Different vendors use different baseline periods, return periods, and bias-correction methods.
- Emissions factors. Pulled from databases like ecoinvent, IEA, or government inventories. Versions change. Methodological updates can shift reported Scope 3 totals by double-digit percentages year over year.
- Scenario outputs. Internally computed from model runs that may live on individual analysts’ laptops, with parameter sets that are not always checked into anything resembling source control.
- Counterparty data. For financed emissions and physical risk in lending books, banks need granular asset-level data on counterparties. This is the worst-quality category by a wide margin.
The pattern across all five: the science is solvable, the lineage is not — at least not by the methods most teams currently use.
What an auditor will actually ask
The questions that surface in the first restatement cycle are not about scenarios or methodologies. They are operational:
- “Show me the version of the hazard layer used for this 2025 disclosure. Is the same version still retrievable today?”
- “The Scope 3 emissions number changed by 8% between the prior-year restatement and this year’s filing. Which factor change drove that, and was the prior-year number recalculated using the new factor or the original?”
- “This asset location list contains 2,847 sites. The procurement register shows 3,102 active sites at year-end. What reconciles the difference?”
- “The transition scenario uses a 2°C pathway. Which NGFS vintage? Phase 4 or Phase 5? Which downscaling method?”
These are not novel questions. Auditors ask them every year about the rest of the financial statements. The novelty is that climate data was historically held to a softer standard, and that softer standard is now gone.
What a defensible architecture looks like
The teams that will not be rewriting their disclosure pipelines in 2027 are the ones building the same primitives the rest of the finance function already relies on:
- Versioned data sources. Every input — hazard layer, emissions factor table, scenario output — committed to a content-addressable store with an immutable version identifier. DVC, lakeFS, or even a disciplined git-LFS setup all work. The detail matters less than the discipline.
- Explicit data contracts. Each upstream source has a schema, a refresh cadence, and a documented owner. When a vendor changes their methodology, the change shows up as a contract violation, not as a silent shift in the reported numbers.
- Reproducible computation. The transformation from raw inputs to disclosed numbers is a single executable pipeline. Re-running it with the same inputs produces the same outputs, byte-for-byte. This is what makes restatement tractable.
- Audit-grade logging. Every disclosed number has a traceable lineage back to specific input versions, transformation code commits, and execution timestamps. This is the part that takes the longest to build and is the most painful to retrofit.
- Separation of vendor data and internal computation. Vendor APIs and PDFs are pulled into a controlled internal layer first, with provenance metadata attached, before any analytical use. This prevents the worst failure mode: a vendor silently updating yesterday’s number under today’s URL.
Why finance teams should own this, not sustainability teams
The instinct in many organisations is that climate disclosure is “sustainability work” and therefore lives under the CSO. That allocation made sense when CSR reporting was voluntary and read mostly by NGOs. It does not survive the move into the financial reporting perimeter.
The function that already operates versioned data lakes, change-controlled pipelines, and audit-grade lineage is the finance data team. They have the muscle. The sustainability team has the domain knowledge. The reporting outcome will be better when the finance data platform is the substrate and sustainability sits on top of it, not when the sustainability team tries to build a parallel data infrastructure from spreadsheets.
The companies getting this right in 2026 are the ones that quietly moved climate data ownership into the finance technology stack last year. The companies that will struggle in 2027 are the ones still treating it as an ESG project.
At Skaraz Data, we build climate and physical risk data pipelines with the lineage, versioning, and audit trail that IFRS S2 actually requires. If your team is staring at the gap between what your sustainability function produces and what your auditor will accept, let’s talk.