Europe’s flood radar is back online, and almost nobody on the insurance modeling side is talking about what that gap actually cost.
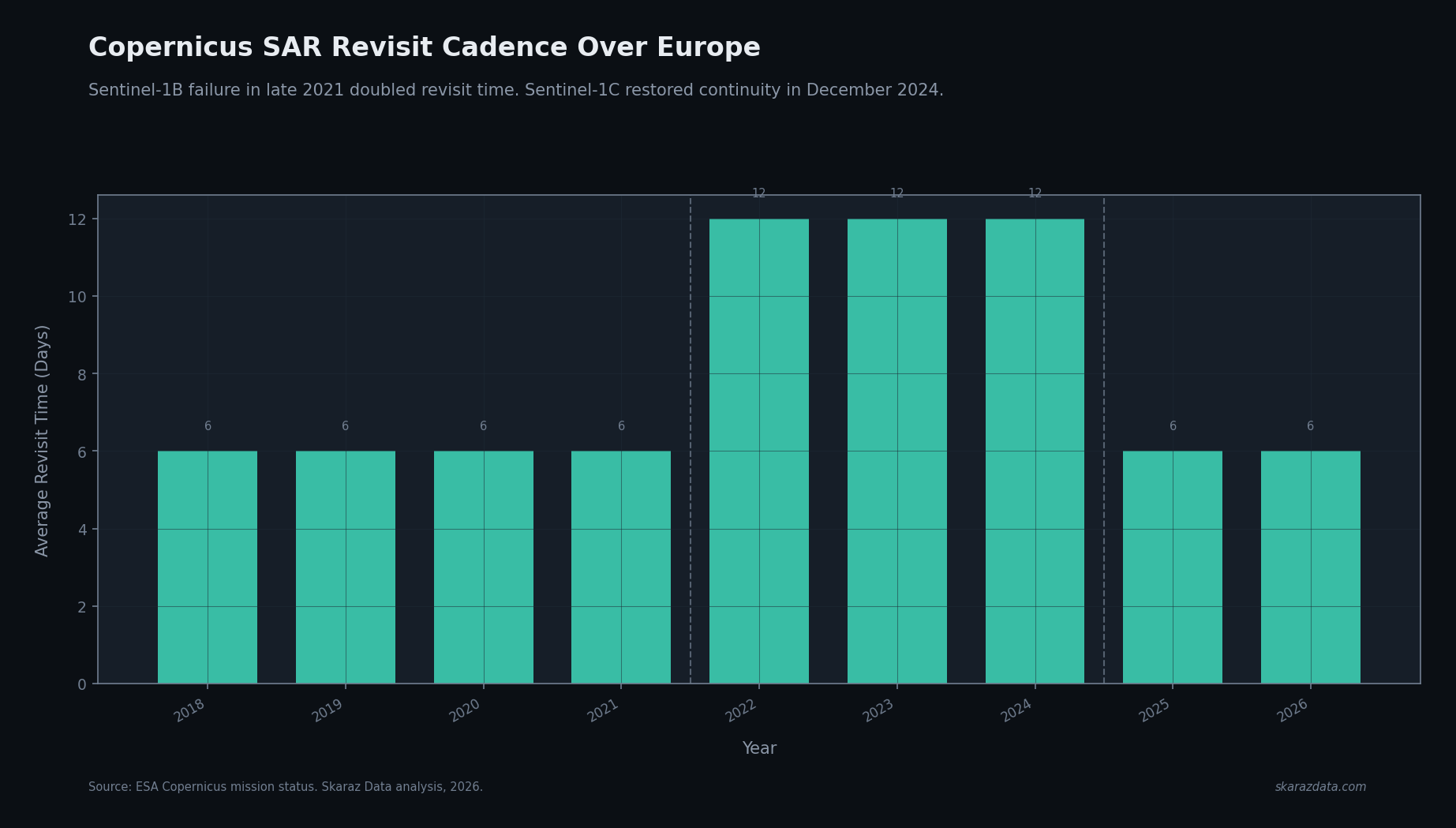
Sentinel-1C launched on a Vega-C from Kourou on 5 December 2024, restoring the Copernicus SAR constellation after Sentinel-1B’s power failure in December 2021. Three years of degraded coverage. For flood modelers, that gap is not a footnote. It sits inside the calibration window of every model trained on the post-2022 record.
What the gap actually was
When both Sentinel-1A and Sentinel-1B were operational, the effective revisit time over Europe was around 6 days. After 1B failed, that doubled to 12 days for most of the continent. Some priority areas were covered better, some worse, but as a planning baseline the cadence halved.
A 12-day revisit means a flood event that peaks and recedes within a week may simply not be observed. SAR is not optional here: it is the only sensor type that reliably penetrates cloud cover during the event itself. Optical satellites are useless mid-storm. Drones cannot fly safely. Ground gauges are sparse. SAR is the source of truth for inundation extent, and for three years it was sampling at half the rate.
Why this matters for calibration
Most modern flood model validation loops compare modeled return-period footprints against observed inundation extents from recent events. The implicit assumption is that the observation set is a representative sample of what actually happened.
During the gap that assumption breaks in three ways:
- Short-duration events are systematically undersampled. Flash floods that peak and drain in under 96 hours have a real chance of falling between Sentinel-1A passes. They are present in claims data but absent from the SAR record.
- Coverage bias by latitude and orbit geometry. Some regions retained near-original cadence because of overlapping ascending and descending passes. Others lost more than half. Any aggregate validation that pools observations across Europe inherits that bias.
- Commercial SAR partially filled the gap, but not uniformly. ICEYE and Capella delivered tasked acquisitions over major events, but tasking is reactive and biased toward already-newsworthy floods. Smaller events stayed dark.
If your model’s recent calibration weights post-2022 events heavily, you are calibrating against a biased sample. The bias is small for set-piece events like the 2024 Valencia floods that triggered massive commercial tasking. It is large for the long tail of mid-sized events that drive the bulk of claims frequency.
What to actually do
For teams running flood model validation pipelines, the practical actions are concrete:
- Re-flag the 2022–2024 calibration period as reduced-confidence in your model documentation. This is not a cosmetic change. It affects how downstream users should weight recent skill metrics.
- Pull the Copernicus EMS rapid mapping archive for the gap years. EMS activations are biased toward large declared disasters but provide a more complete event list than SAR alone for that period.
- Quantify the undersampling: cross-reference your claims database against the SAR observation record. Events with claims but no SAR coverage are exactly the events your model should be tested against once Sentinel-1C operational data is available at scale.
- Plan a recalibration window. Sentinel-1C reached its operational orbit in early 2025. By mid-2026 there will be 12+ months of restored 6-day cadence data. Build that into your model release schedule, not into next year’s “if we have time” backlog.
The broader pattern
This is the second time in a decade that a Sentinel-1 outage has quietly degraded a piece of insurance infrastructure that nobody had on a risk register. The first was the Sentinel-1B failure itself. The lesson is not that satellite data is fragile. The lesson is that calibration data is infrastructure, and infrastructure outages have multi-year tails even after service is restored.
The teams that treat the SAR record as a versioned, auditable input — with explicit coverage metrics over time — will catch this kind of degradation in real time. The teams that treat it as a black-box feed will discover it the next time a regulator asks why their 2023 model skill numbers look better than they should.
At Skaraz Data, we build calibration and validation pipelines for flood and hazard models, including coverage-aware metrics that explicitly track satellite observation density alongside model skill. If your team is working through what the SAR gap means for your 2026 model release, let’s talk.